Decoding the Structural DNA of Nepali News: A Statistical Odyssey
The Objective
What happens when you treat language not as a set of rules, but as a massive statistical engine? This research explores a corpus of 200,000 Nepali news articles to find the hidden signatures that govern how words collaborate, compete, and cluster. We move beyond simple "counting" to map the informational physics of the Nepali language.
Part I: The Law of the Few (Natural Order)
Before analyzing relationships, we must confirm we are looking at natural language and not noise.
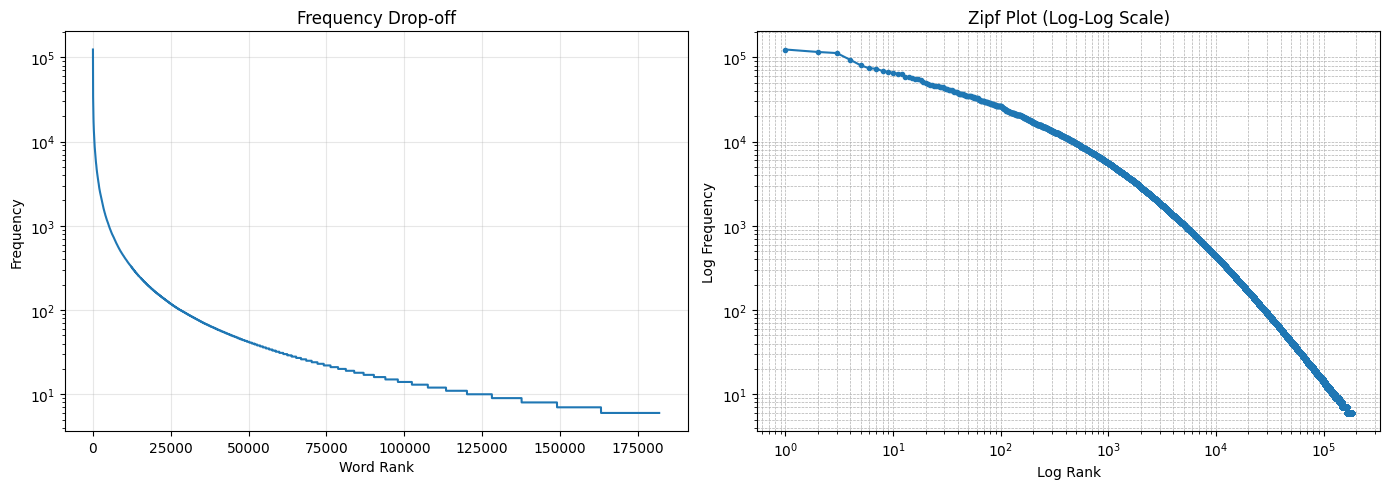
Zipf’s Law tells us that the frequency of any word is inversely proportional to its rank. When we plotted our 200k articles, the "Long Tail" was unmistakable.
- The Statistics: A tiny subset of "heavy" words—नेपाल (124,197 occurrences), गरिएको (116,088), and काठमाडौं (112,703)—form the structural bones of the language.
- The Finding: Our dataset perfectly obeys Zipf's distribution, proving it is a mathematically "complete" representation of the Nepali news ecosystem.
Part II: Semantic Magnetism (How Words Stick)
If the language has a skeleton, then PMI (Pointwise Mutual Information) is the muscle that pulls words together.
We measured the "magnetic pull" between words. Beyond simple counts, we looked for pairs that appear together way more often than chance (High PMI).
- Sticky Pairs: The data revealed almost inseparable bonds like ऊर्जा (Energy) and जलस्रोत (Water Resources), or the unbreakable political bigram केपी शर्मा (22,985 occurrences).
- The Entropy Connection: We found that high-frequency context words like नेपाल have High Entropy (broad, unpredictable usage), while specific names like केपी have Low Entropy because they are almost 100% predictive of the word शर्मा.
Part III: The Surprise Factor (The Information Pivot)
Using KL Divergence and Bayesian Inference, we identified how much "information" a word actually adds to a sentence.
- Bayesian Logic: If you see the context word प्रधानमन्त्री (Prime Minister), the probability of the next word being केपी jumps significantly. This isn't just a guess; it's a measurable probabilistic shift.
- Information Surprise: Using KL Divergence, we identified "Anchor Words" like मौसम (Weather) or स्वास्थ्य (Health). These words carry so much thematic weight that they pivot the entire sentence's meaning, drastically narrowing down the "search space" for what follows.
Part IV: The Emergent Ecosystem (The Final Graph)
The most profound finding is how the microscopic "stickiness" of individual word pairs creates a macroscopic "map of meaning."
When we visualized these connections, we didn't get a tangled mess. Instead, we saw the birth of thematic islands.
- Thematic Core: Politics forms the densest cluster (the नेकपा एमाले and नेपाली कांग्रेसका groups).
- Social Peninsulas: Clusters for प्रहरी (Police/Security) and आर्थिक (Economy) form distinct neighborhoods.
- Consistency: The "islands" below are the physical manifestation of our PMI and KL Divergence results—groups of words bound by high mutual magnetism.
Synthesis: A Coherent Story
This research proves that language is consistent across scales:
- Global Scale: Follows a strict power-law distribution (Zipf).
- Local Scale: Words are bound by probabilistic "glue" (PMI) and Bayesian dependencies.
- Macro Scale: These local bonds aggregate into logical, navigable thematic clusters.
Implementation & Source
Find the complete implementation, unigram/bigram counters, and the interactive network graph code at: statistical-analysis-nepali-corpus