Introduction: Why This Work Exists
Nepali is spoken by over 20 million people, yet it remains severely underserved in NLP research. Most existing work focuses on classification, translation, named entity recognition, and POS tagging. Creative text generation in Nepali had no prior work at all.
This project fills that gap. The goal was to build a system that generates culturally grounded, poetically coherent Nepali song lyrics using transformer-based language models, starting from scratch: no existing lyrics dataset, no prior generative baseline, no playbook to follow.
Beyond the technical contribution, this work establishes the first perplexity benchmarks for Nepali creative text generation, making it a reference point for future research in low-resource creative NLP.
The Core Problem
Two problems compound each other in low-resource creative NLP:
- Data scarcity. Only ~1,700 authentic Nepali song lyrics could be collected. That is far too little to fine-tune a language model from scratch without severe overfitting.
- Domain mismatch. The only available pretrained Nepali GPT-2 model (
GPT2_Nepali_124M) was trained on formal news text. Song lyrics are structurally and stylistically opposite to news: fragmented, repetitive, metaphor-heavy, and rhythmically structured.
Bridging that domain gap, with limited real data, was the central research question.
Approach: Four Models, One Lineage
Rather than training a single model, this project designed a progressive model lineage to isolate the effect of each data type and training strategy.

| Model | Training Data | Purpose |
|---|---|---|
| Model 0 (Zero-Shot) | Pre-trained only | Baseline: how bad is the domain mismatch? |
| Model 1 (Fine-Tuned) | 1.7K real lyrics | Upper bound on real-data-only training |
| Model 2 (Domain-Adapted) | 7.9K synthetic lyrics | Does synthetic volume help bridge the domain gap? |
| Model 3 (Hybrid) | Synthetic → then real lyrics | Does gradual fine-tuning beat direct fine-tuning? |
The key insight driving this design: gradual fine-tuning (pretrain on synthetic, then fine-tune on real) prevents catastrophic forgetting, a known failure mode when domain-adapting language models on small datasets.
Dataset Construction
Real data was manually curated. There is no existing Nepali lyrics corpus, so 1,700 authentic songs were collected by hand. This gives the model cultural grounding and genuine poetic style.
Synthetic data was generated at scale using three strategies:
- Back-translation: Nepali text translated to English and back to Nepali via LLMs, producing paraphrastic variation.
- Paraphrasing: Existing lyrics rewritten at the sentence level to expand vocabulary diversity.
- Description-to-lyrics: English descriptions of lyrical themes were fed to LLMs to generate Nepali lyrics from scratch.
The synthetic corpus reached 7,900 samples, giving the domain adaptation stage (Model 2) enough volume to shift the model away from news-style generation before real lyrics were introduced.
Split: 80% train / 20% validation across all variants.
System Design
The full pipeline runs from raw text to trained model to generated output:
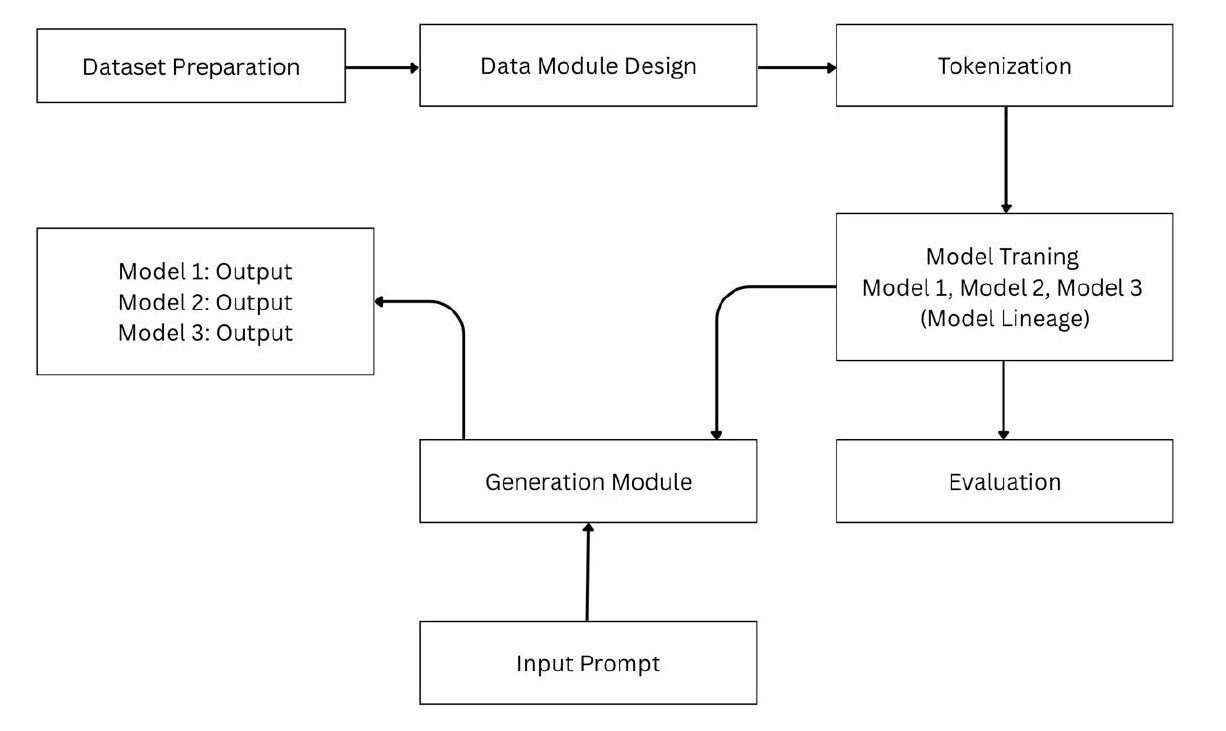
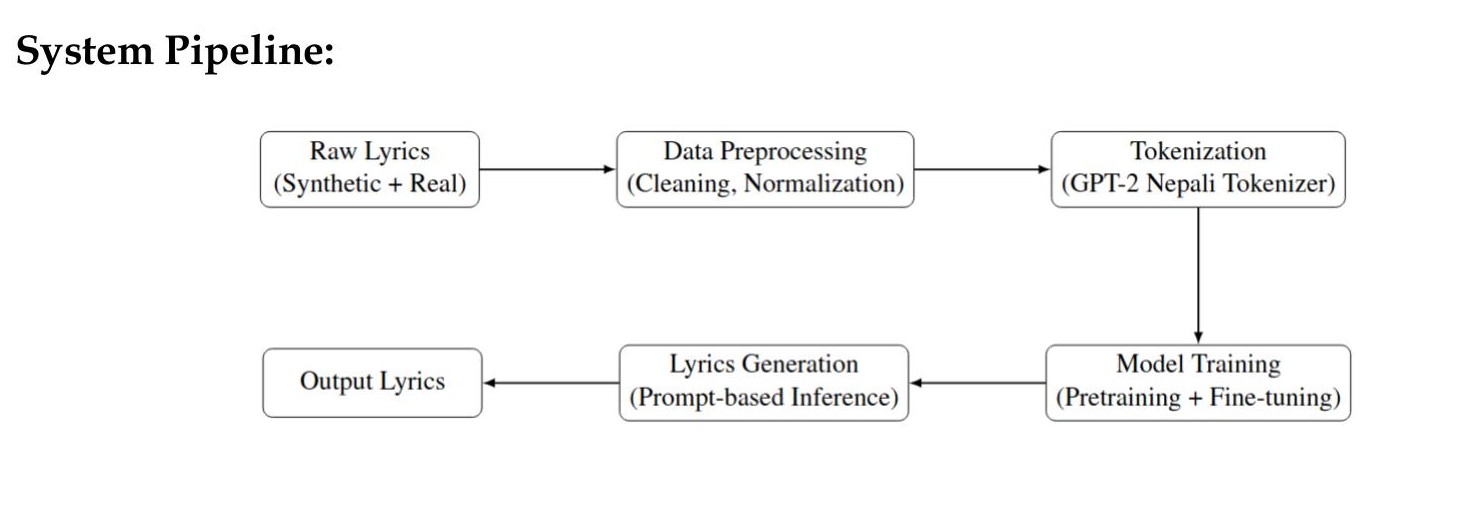
Stack: Python 3.10, PyTorch 2.0, Hugging Face Transformers, Kaggle P100 GPU (16 GB).
All models are uploaded to Hugging Face for reproducibility:
bhaveshadhikari/base-og-tuned(Model 1)bhaveshadhikari/syn-tuned(Model 2)bhaveshadhikari/syn-og-tuned(Model 3)
Training Configuration
- Architecture: GPT2_Nepali_124M — 12 layers, ~124M parameters, BPE tokenization for Devanagari
- Generation: top-k sampling (k=50), nucleus sampling (p=0.95), temperature 0.8
- Model 1 & 3: LR = 2e-5, 15–20 epochs
- Model 2: LR = 1e-5, 3–5 epochs (17,000 steps on synthetic corpus)
- Batch size: 2 with gradient accumulation of 4 (effective batch = 8)
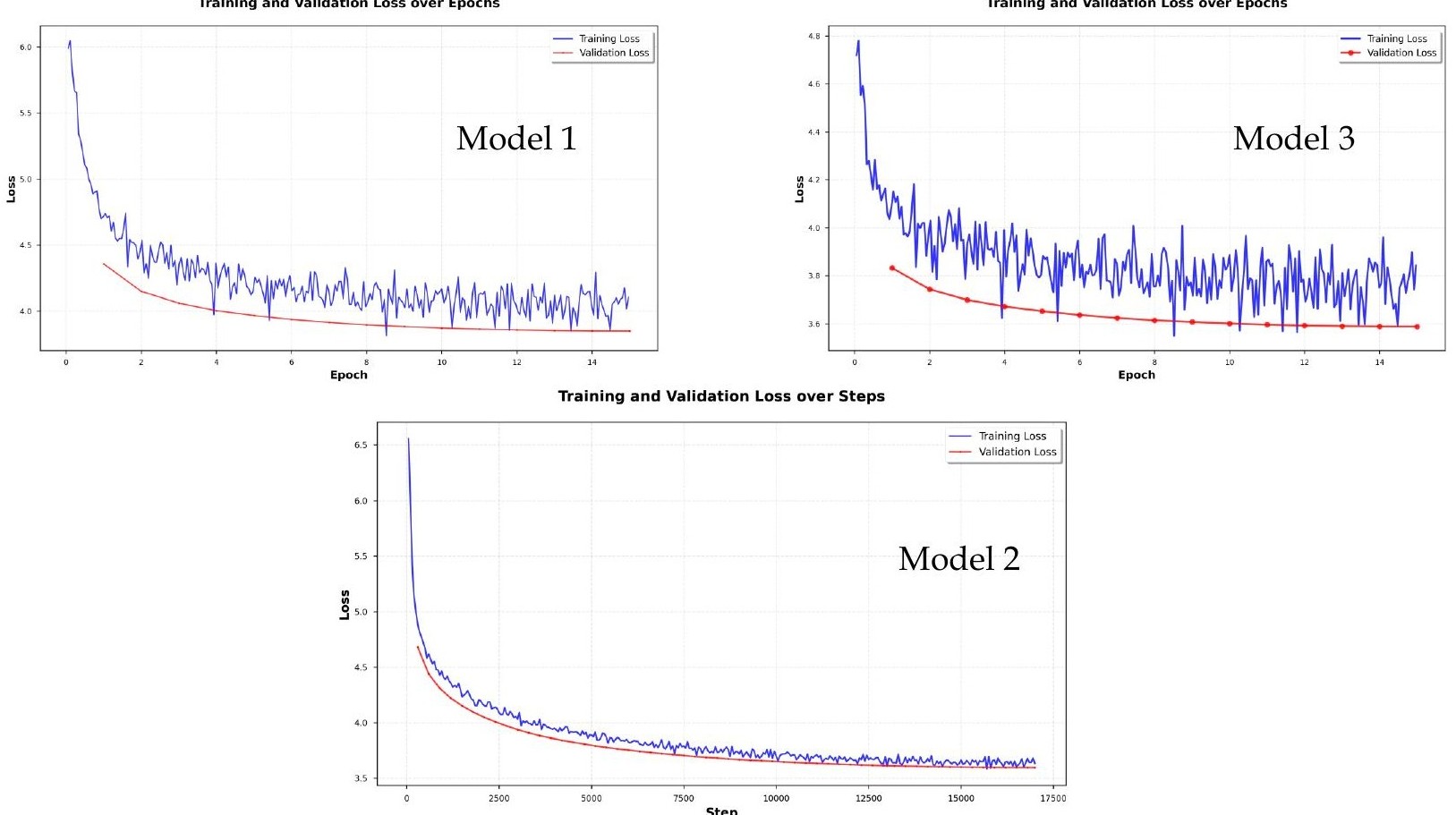
All three models converge cleanly. Model 3 notably starts from a lower initial loss than Model 1, confirming that domain adaptation on synthetic data provides a better initialization for fine-tuning on real lyrics.
Results
Quantitative: Perplexity
| Model | Perplexity | vs. Baseline |
|---|---|---|
| Base (Zero-shot) | 228.83 | — |
| Base + Real | 42.01 | 5.4× better |
| Base + Synthetic | 36.50 | 6.3× better |
| **Base + Synthetic + Real** | **33.40** | **6.9× better** |
The hybrid model (Model 3) achieves the lowest perplexity at 33.40, a 6.9× improvement over the zero-shot baseline. Critically, even the synthetic-only model (Model 2, perplexity 36.50) outperforms the real-data-only model (Model 1, perplexity 42.01), confirming that volume from synthetic data provides a stronger domain signal than quality alone.
Qualitative: Human Inspection
- Model 0: Formal, news-like prose. No lyrical structure.
- Model 1: Some metaphors, limited vocabulary, frequent repetition.
- Model 2: Richer metaphors and lexical diversity, occasional grammatical awkwardness.
- Model 3: Coherent verse structure, culturally grounded imagery, poetic register, occasional repetition.
Sample Generations

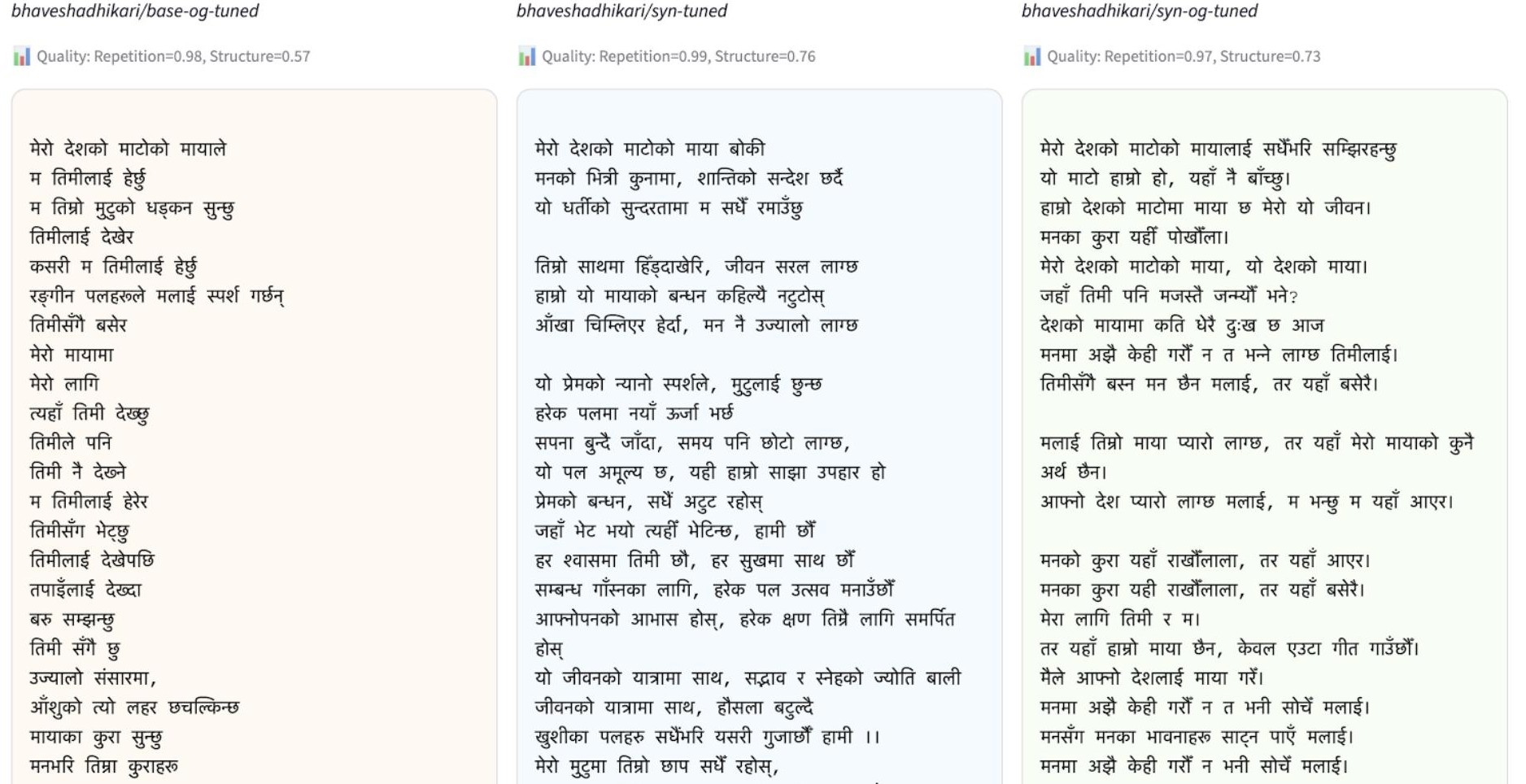
The progression from Model 1 to Model 3 is visible in the outputs. Model 1 tends to loop a single phrase. Model 2 introduces diversity but at the cost of fluency. Model 3 sustains both coherence and variety across multiple stanzas.
Key Contributions
- First generative NLP work on Nepali creative text. No prior system existed for Nepali lyrics, poetry, or any open-domain creative generation.
- Novel bilingual dataset. 1,700 curated real Nepali lyrics + 7,900 synthetic samples, constructed entirely from scratch.
- Validated the synthetic augmentation pipeline for low-resource creative NLP. Synthetic data alone (Model 2) outperformed real-data fine-tuning (Model 1).
- Established perplexity baselines for future Nepali generative NLP research.
- Public model releases on Hugging Face for reproducibility and community reuse.
Limitations
- Single model architecture (GPT-2). No comparison against mT5, mBART, or multilingual LLMs.
- Unconditional generation: the model does not condition on emotion, genre, melody, or rhythmic structure.
- Perplexity does not fully capture creative quality. A formal human evaluation study with Likert-scale ratings would strengthen the evaluation.
- No multimodal output: audio or melody generation is outside scope.
- Models may hallucinate in a non-deterministic manner on non-lyrical prompts.
Citation
If you use this work, dataset, or models, please cite:
@thesis{adhikari2025nepalilyrics,
title = {A Transformer-Based Approach to Nepali Lyrics Generation},
author = {Adhikari, Bhavesh},
year = {2025},
school = {Tribhuvan University, Mahendra Morang Adarsha Multiple Campus},
type = {Bachelor's Thesis},
note = {BSc. CSIT}
}References
- Malmi et al., "DopeLearning: A computational approach to rap lyrics generation," ACM SIGKDD 2016.
- Radford et al., "Language models are unsupervised multitask learners," OpenAI Blog, 2019.
- Li et al., "Synthetic data generation with LLMs for text classification," EMNLP 2023.
- Dai et al., "Overcoming data scarcity in NER," BioNLP Workshop, 2025.
- Xu et al., "Gradual fine-tuning for low-resource domain adaptation," Domain Adaptation for NLP Workshop, 2021.
- Shahi and Sitaula, "Natural language processing for Nepali text: A review," Artificial Intelligence Review, 2021.
- Thapa et al., "Development of pre-trained transformer-based models for the Nepali language," arXiv:2411.15734, 2024.